
Daha önce veri kalitesini düşüren problemlere çözümler için ML.net ile bir yazı hazırlamıştım. Yazıda bize gelen verideki tekrarlı kayıtlar, sapan değerler, eksik değer gibi verinin toplanması sırasında yaşanmış olması olası problemleri çözmüştük. Fakat hayat hep cilvesini yapar. Elimizde tertemiz verimiz olduğu halde de başarılı sonuçlar alamayabiliriz. Bu problemlerden bir tanesi verinin belirli türe yoğunlaşması sebebiyle yani dengesiz sınıf dağılımı nedeni ile yaşanır.
İşin Mantığı
Bunu en güzel örnek veri ve grafik anlatır sanırım. Veriyi inceleyin:
| X | Y | LABEL |
|---|---|---|
| 10000 | 25 | A |
| 25000 | 30 | A |
| 12500 | 32 | A |
| 9000 | 20 | A |
| 20000 | 40 | A |
| 5000 | 20 | A |
| 28000 | 35 | A |
| 6000 | 22 | A |
| 5900 | 23 | A |
| 4900 | 19 | A |
| 5000 | 24 | A |
| 5500 | 23 | A |
| 10000 | 40 | B |
| 12000 | 65 | B |
| 9000 | 40 | B |
| 12000 | 65 | B |
| 2000 | 20 | B |
| 4000 | 30 | B |
| 6000 | 25 | B |
| 9000 | 60 | B |
A sınıfından bolca, B sınıfından az miktarda olan verimiz var. Bu gerçek verilerde de sık karşılaştığımız bir durum. Bazı sınıflara ait örneklerin bulunması kolay veya mümkün olmamaktadır. Örneğin, oyuncu veritabanında hile yapan oyuncuların sayısı az olabilir. Şayet doğrudan masum/hilebaz şeklinde tüm veri alındığında algoritma tarafından bir çok hilebaz masum olarak tahmin edilebilir. Örnek verimize dönelim ve grafik üzerinde gösterelim, böyle daha anlamlı gelecektir:
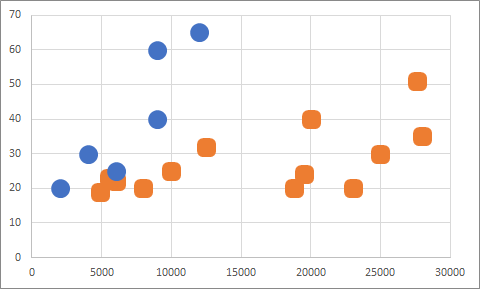
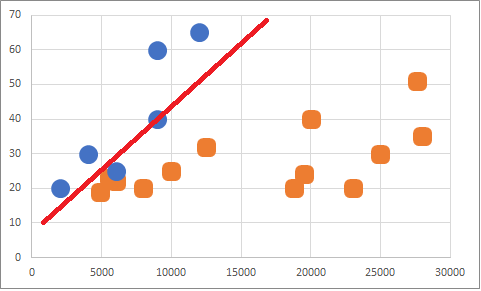
Bu veri ile bir makine öğrenmesi gerçekleştirdiğimiz takdirde bir çok algoritma için A sınıfına doğru bir kayma gerçekleşecektir. Ayırma işlemi aşağı yukarı şöyle olur.
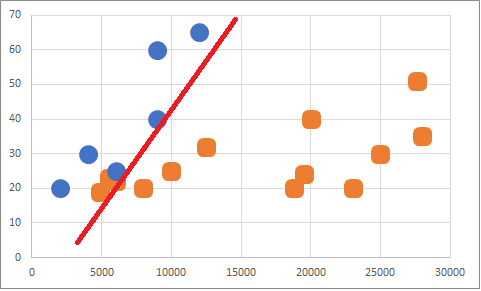
Fakat yeterince B verisi olsaydı bu çizginin aşağıdaki gibi olması makul olabilirdi.
Azure ML Studio ile bu veriyi bir ikili SVM sınıflandırıcısına koyduğumda SMOTE uygulamadan 0.46 f1 score alırken, algoritma uygulandığında 0.7 değerini aldım. Tabii bu kadar az veri ile bu pek bir anlam ifade etmiyor ama fikir vermesi açısından önemli. Ayrıca benim senaryomda F1 score arttı ama aslında SMOTE gibi algoritmalarda amaç Recall değerini arttırmaktır.
Algoritma
SMOTE (Synthetic Minority Oversampling Technique) sınıfları dengeli hale getirmektedir. Peki bunu nasıl yapacak. Öncelikle azınlık olan sınıfı ne kadar oranda çoğaltmak istediğimize karar veriyoruz. İşi basit tutmak için %100 diyelim. Bu durumda her bir azınlık örneği için bir nokta daha üretilecektir.
Daha sonra üretim için en fazla kaç nokta uzağa gideceğini belirleyeceğiz. Yine hesap kolaylığı için buna da 2 değerini vermiş olalım.
Tüm noktaları sıra ile dönmemiz gerekecek, ilk noktamız mor olarak işaretlenmiş nokta olsun.
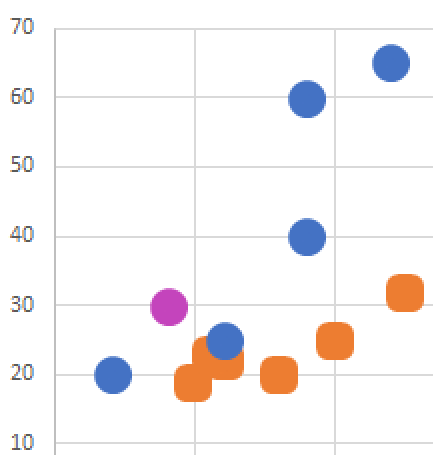
Bu noktaya en yakın 2 noktayı belirliyoruz bunlarda yeşil noktalar olsun.
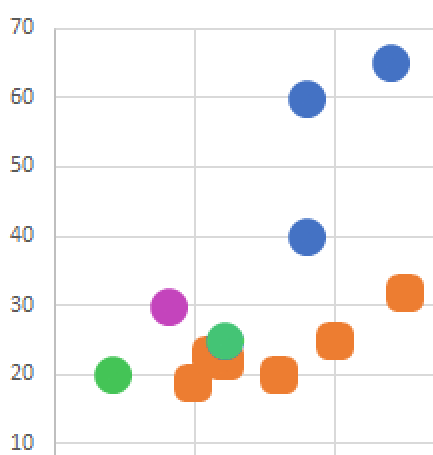
Bu noktalardan rastgele bir tanesini seçiyoruz.
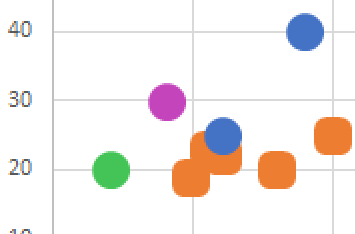
Daha sonra bu iki nokta arasında kalan bölge içerisinde rastgele başka bir nokta daha üretmem gerekecek. Arada kalan bölge resimdeki kırmızı bölge oluyor.

Ürettiğimiz nokta da örneğin resimdeki siyah nokta olsun:

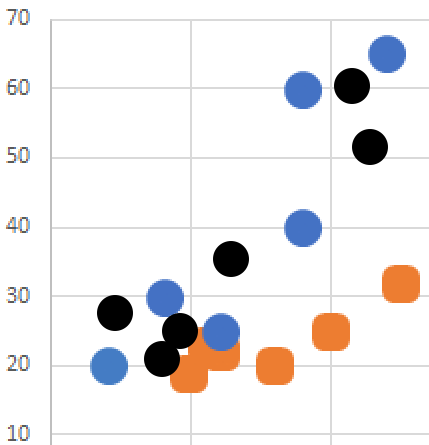
Aynı mantığı her nokta için tekrarladığımızda aşağıdaki gibi görünüm elde ederiz.
Kodlayalım
Adım 1 Uzaklık Fonksiyonu
İlk ihtiyacımız iki örnek arasındaki uzaklığı hesaplayacak bir fonksiyon. Örneğimizde Öklid uzaklığından gideceğiz. Hatırlarsanız kendisinden eski yazılarda bahsetmiştim. Kabaca n boyutlu düz uzayda uzaklık ölçmek için kullanıyordu.
public double Uzaklik(double[] p1, double[] p2)
{
return Math.Sqrt(Enumerable.Range(0, p1.Length).Sum(i => p1[i] - p2[i]));
}Adım 2 En yakın noktaları bulma fonksiyonu
Verilen bir noktaya en yakın n sayıda noktanın indislerini dönen bir metot hazırlıyoruz.
public int[] EnYakinlariBul(double[][] uzay, int kaynakNoktaIndis, int n)
{
var kaynakNokta = uzay[kaynakNoktaIndis];
return uzay.Select((x, i) => (Nokta: x, Indis: i))
.OrderBy(x => x.Indis == kaynakNoktaIndis
? double.MaxValue
: Uzaklik(kaynakNokta, x.Nokta))
.Take(n)
.Select(x => x.Indis)
.ToArray()
}Sorgu kısmı önce indisleri içeren bir tuple oluşturuyor böylece sonradan gerçek indislerin ne olduğunu bilebileceğiz, ardından uzaydaki her noktanın kaynak noktaya göre uzaklığını alıyor. Buradaki ufak dokunuş, noktanın kendisi için uzaklık maksimum kabul ediliyor. Sonra bu uzaklık ölçümlerine göre küçükten büyüğe sıralama işlemi yapılıp ilk n adet değer alınıyor. Bu değerlerin içinde bizi ilgilendiren orijinal dizideki indis değerleri olduğundan son bir Select ile bunları alıyoruz. Son adımda ToArray ile sorguyu bir diziye çevirip işlemi tamamlamış oluyoruz.
3 Sentetik noktaların oluşturulması
double[][] Smote(double[][] uzay, double buyumeOrani, int tohum, int bakilacakUzaklik)
{
var random = new Random(tohum);
var noktaBasiAdet = (int)(buyumeOrani / 100);
var uretimIndis = 0;
double[][] uretilenler = new double[noktaBasiAdet * uzay.Length][];
var boyut = uzay[0].Length;
for (int mevcutNoktaIndis = 0; mevcutNoktaIndis < uzay.Length; mevcutNoktaIndis++)
{
var enYakin5Nokta = EnYakinlariBul(uzay, mevcutNoktaIndis, bakilacakUzaklik);
var uAdet = noktaBasiAdet;
while (uAdet > 0)
{
var secilenNokta = uzay[enYakin5Nokta[random.Next(0, bakilacakUzaklik)]];
var mevcutNokta = uzay[mevcutNoktaIndis];
uretilenler[uretimIndis] = new double[boyut];
for (int nitelik = 0; nitelik < boyut; nitelik++)
{
var fark = secilenNokta[nitelik] - mevcutNokta[nitelik];
var bosluk = random.NextDouble();
uretilenler[uretimIndis][nitelik] = mevcutNokta[nitelik] + (bosluk * fark);
}
uretimIndis++;
uAdet--;
}
}
return uretilenler;
}Kodumuz aslında görsel olarak ifade ettiğim adımları uyguluyor.Yine de adım adım takip edecek olursak. Rastgele sayı üreticisini hazırlayarak başlıyoruz. Her bir nokta için üretilecek adedi belirliyoruz. Üretilen noktalar için bir jagged array tutuyoruz. Boyutu zaten girdi olarak gelmişti, çarpma işlemi ile boyutu netleştiriyoruz. Her bir azınlık noktasını tek tek dolaşıyoruz. Noktaya en yakın arkadaşlarını bulup arasından rastgele bir tanesini seçiyoruz. Noktanın her bir boyutu için iki nokta arasındaki mesafe içinde rastgele konumda bir nokta daha üretiyoruz ve üretim listesine ekliyoruz. Üretim listesini geri dönerek bitiriyoruz.
Daha sonra kullanırken,
var veri = new[] { new[] { 1.0, 10.0 },
new[] { 1.1, 20.0 },
new[] { 1.2, 30.0 },
new[] { 1.3, 40.0 },
new[] { 1.4, 50.0 },
new[] { 1.5, 60.0 },
new[] { 1.6, 70.0 },
new[] { 1.7, 80.0 },
new[] { 1.8, 90.0 },
};
var sonuc = Smote(veri, 100, 1,5);şeklinde kullanabiliriz.Not olarak algoritma istenirse %100'ün altında değer üretecek şekilde ayarlanabilir bu durumda, tüm noktalar için değer seçilemeyeceğinden azınlık noktaları içinden rastgele noktalar seçerek ilerleyecek biçimde bir algoritma geliştirilebilir.
Literatürde sınıfları dengelemek için bir çok yöntem ve bu yöntemlerin varyasyonları bulunmaktadır. SMOTE'un da bir çok varyasyonuna rastlayabilirsiniz. Bu yazıda en temel halini ele aldım.
İlerideki yazılarda görüşmek üzere

güzel bir anlatım olmuş, tebrik ederim