
Bir önceki yazıda sıfırdan C# ile K-Means algoritmasını yazmıştık. Yine algoritmanın nasıl çalıştığını bu yazıda detaylıca anlatmıştım. Bu yazıda ise bu algoritmayı Azure ML Studio üzerinde nasıl kullanabileceğimizin detaylarına gireceğiz.
☁ Azure ML Studio'da nedir? diyorsanız sizi Merhaba Azure ML Studio yazıma alayım.
Veri Hazırlığı
Bu yazıda hem bir önceki yazıda nasıl çalıştığını anlattığım K-Means algoritmasının biraz daha detayına inmek, hem de Azure ML Studio üzerinde örneklemek istedim. O sebeple karmaşık veriler yerine önceki yazıda ürettiğimiz veriyi kullanacağım. İlerleyen günlerde daha az konu anlatımı olan doğrudan problem çözümüne yönelik yazılar yazmayı planlıyorum. Hemen konuya dönelim. Bir önceki yazıda ürettiğimiz verinin CSV biçimindeki hali aşağıdaki gibidir.
X,Y
3,5
10,7
5,1
5,2
9,8
8,8
1,1
7,6
6,7
4,3
4,1
5,1
4,2
3,4
8,8
3,5
2,2
2,4
6,7
5,5
5,3
10,7
6,9
2,4
3,3
4,1
1,5
8,10
2,3
10,6Bu veri 2 boyutlu düzlemde şöyle gözüyor:
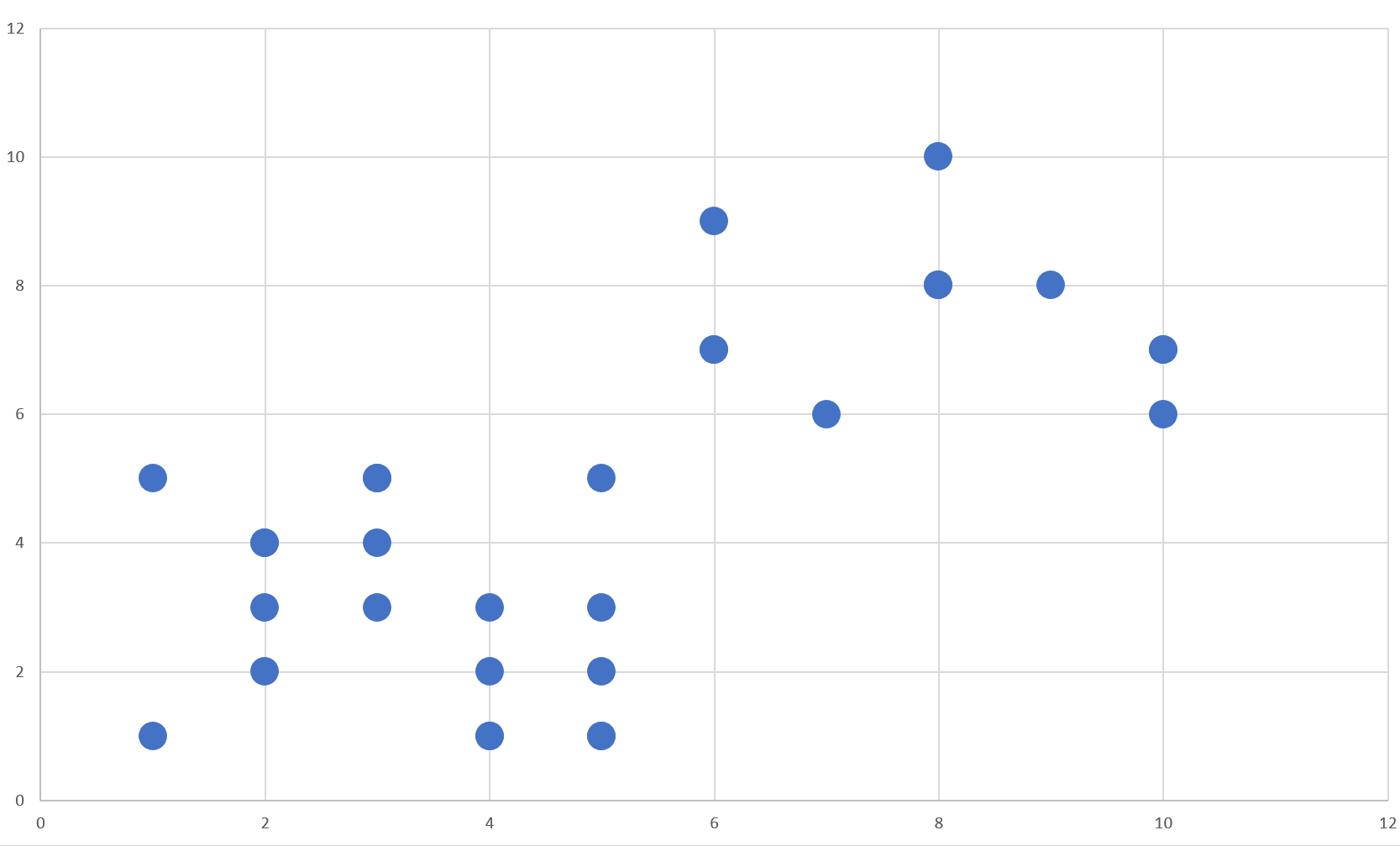
Studio'ya geçiş
Azure ML Studio üzerinde yeni bir deney açıp tuvale "Enter Data Manually" kutusu koyuyoruz. Ve yukarıdaki veriyi kendisinin özellikler penceresinden kopyala-yapıştır yardımı ile yüklüyoruz.
Kaydedip, çalıştırıp verinin düzgün yüklenip yüklenmediğini anlamak için veriyi görselleştiriyoruz:
Herhangi bir sıkıntı gözükmüyor. Tuvalimize öğrenme işini yapması için "Train Clustering Model" kutucuğu bırakıyoruz ve verimize bağlıyoruz.
Özellikler penceresinden kolon seçimi kısmına gelip X ve Y kolonlarımızı seçiyoruz. Daha sonra "K-Means Clustering" kutucuğunu bırakıyoruz ve trainer ile bağlantısını yapıyoruz. Tuvalin son hali aşağıdaki gibi olacaktır:
K-Means Ayarları
Bu ayarların sadece önemli olanlarına ve dokümantasyonda pek değinilmeyen detaylara değindim. Daha fazla detaya ilgili dokümantasyondan ulaşabilirsiniz.
K-Means kutusunun özelliklerine gelelim. Bizi şöyle bir ayar alanı karşılayacak:
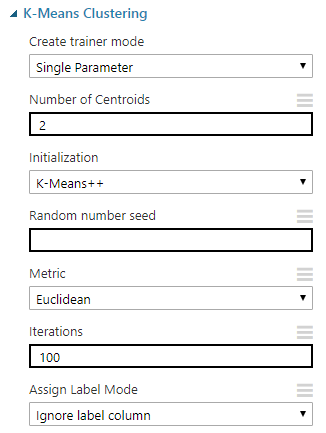
Create trainer mode
| Seçenek | Anlamı |
|---|---|
| Single Parameter | Eğer hangi nitelikleri kullanacağınızdan eminseniz bunu seçin |
| Paramater Range | Kullanacağınız parametrelerden emin değilseniz, Bunu "Sweep Clustering" kutucuğu yardımıyla otomatik deneyecek şekilde yapabilirsiniz |
Number of Centroids
| Seçenek | Anlamı |
|---|---|
| First N | İlk N sayıdaki noktalar kümelerin merkez noktaları olarak kabul edilir |
| Random | Saf K-Means yöntemi, biz de bir önceki yazıda bunu kullanmıştık, tüm noktalar rastgele şekilde N kümeye dağıtılır ve ardından küme merkezleri bu noktalara göre hesaplanır. |
| K-Means++ | Saf K-Means'de rastgele dağıtımda bazen seçimler çok kötü olabilmektedir. Örneğin rastgele belirlenen iki merkez nokta bir birilerine çok yakın olduğunda ilgili konumdaki kümeyi iki parçaya ayırabilmektedir. Bundan kurtulmak ve daha iyi ilk merkez noktaları belirlemek için geliştirilmiştir. |
| K-Means++Fast | K-Means++'ın daha hızlı çalışmayı amaçlayan bir varyasyonudur |
| Evenly | Düzlem üzerinde, düzlemi eşit parçalara ayıran N adet nokta bulunur ve ilk merkez noktaları oluşturur |
| Use label column | Manuel olarak siz belirlersiniz. |
K-Means++
K-Means'deki rastgele başlangıç seçiminde yaşanan problemi özetleyen şu görsellere bir bakın:
N'in 3 seçildiği durumda rastgele noktalar şu şekilde dağıtılmış olsun:
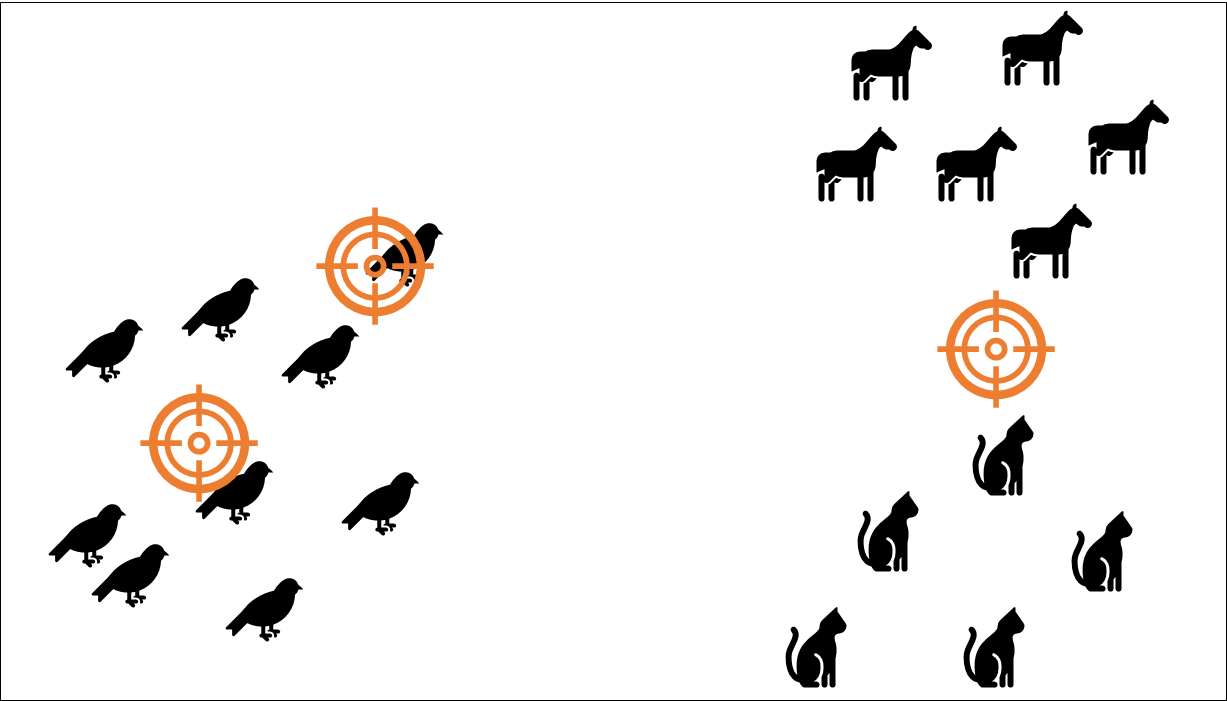
Bununla yapılacak bir kümeleme şu şekilde olacaktır:
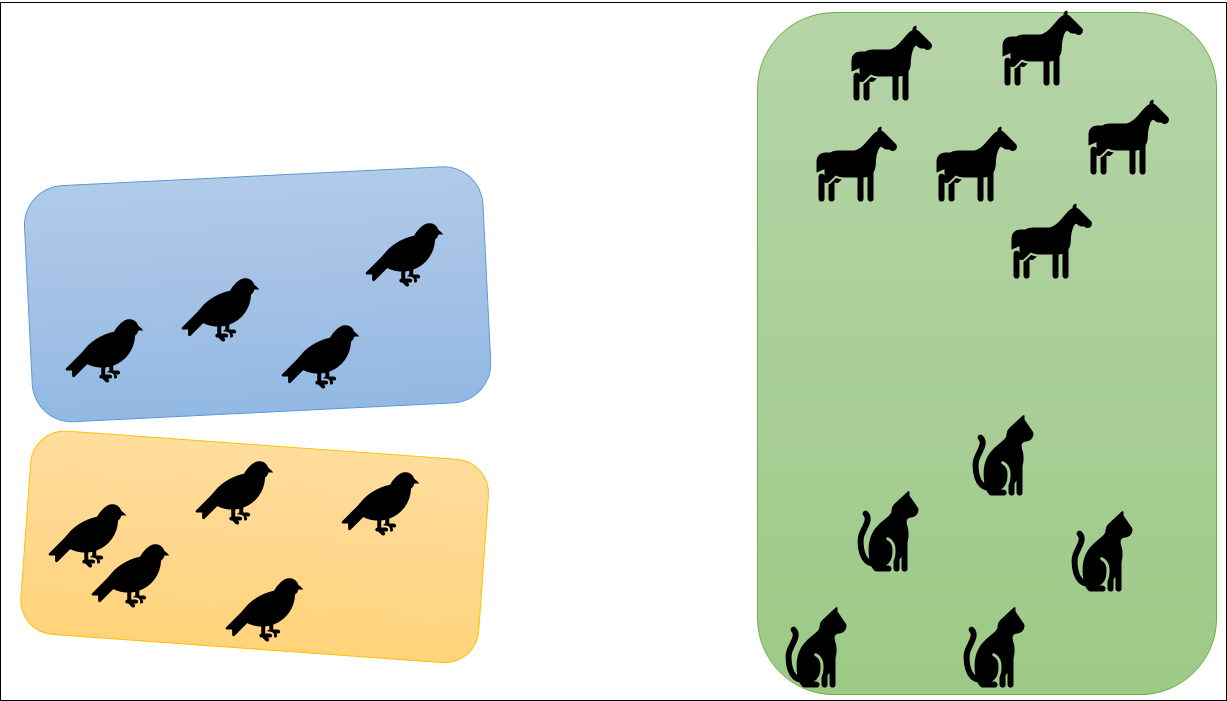
Görüldüğü üzere kuşlar iki farklı kümeye ayrılırken kediler ve atlar aynı kümenin elemanları olmuşlardır. Veri üzerinde az çok fikrimiz yoksa bu tip hatalı başlangıçları pek fark edemeyiz.
Peki K-Means++ bu problemi nasıl çözüyor? İlk noktayı mevcut elemanlardan rastgele birisini seçerek başlıyor:

Daha sonra kalan noktaları bu noktaya olan uzaklıklarına göre ağırlıklandırıyor. Ben yeşil renk ile göstereceğim:

Bir sonraki merkez nokta seçilirken yine rastgele seçilecek ama uzakta olanların yani koyu olanların seçilme şansları açık renk olanlardan daha fazla olacak. Bu arkadaşları birden fazla piyango bileti almış gibi düşünebilirsiniz. İkinci nokta bu duruma göre rastgele seçilsin:

Üçüncü noktaya karar verirken yine her bir nokta için bu sefer kendisine en yakın olan merkez noktaya göre uzaklıklarını ağırlıklandırıyor:
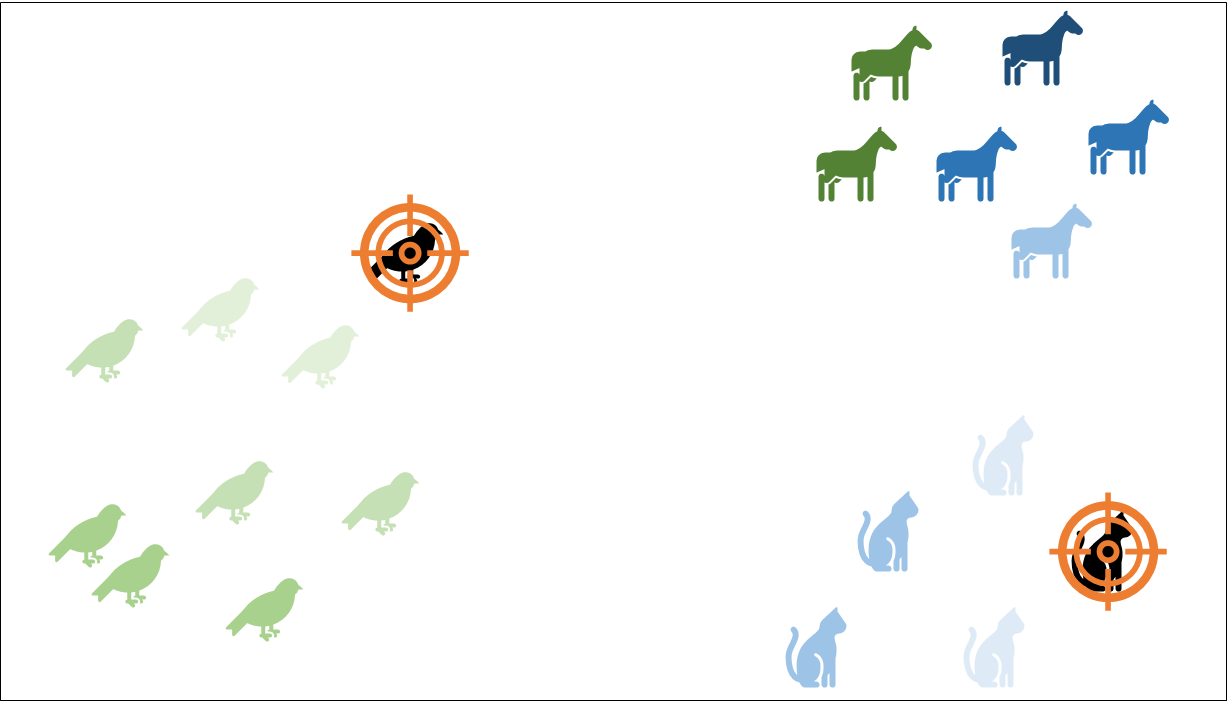
Benzer şekilde daha koyu olan renklerin seçilme ihtimalleri çok daha yüksek. Üçüncü nokta da büyük olasılıkla atların arasından seçilecektir. Hazırladığım görsellerde veri noktası az olduğundan silik renkte olanlardan yine seçim yapılabilirmiş gibi geliyor ama eli yüzü düzgün bir veride binlerce nokta olacağı için birbirine çok yakın iki noktanın seçilme ihtimali yok denecek kadar azalmış oluyor.
Peki ama neden en uzak noktaları seçip geçmiyoruz? Öncelikle veride sapan veriniz olabilir, şu durumu inceleyin:

Bu durumda seçilecek ikinci noktanın sol üst köşedeki kuş olması gerekir. Fakat o seçilirse düzgün bir kümeleme olmayacaktır. Ya da verinin dağılımı en iyi kümelemeyi ancak başlangıç noktalarının belirli yerle gelmesiyle sağlayabiliyordur. Bu durumda rastgele seçimler ile tekrar tekrar hesaplama yapıp aralarından en iyisini seçme yoluna gidebiliriz. Fakat biz hep en uzaktakini seçersek (deterministik yöntem) bu durumda farklılaşma olmayacaktır.
Verinin temizliğinden eminseniz Azure ML de "evenly" modunu tercih edebilirsiniz. Yine de bir miktar deneme yanılma yapmaktan vazgeçmeyin.
Random number seed
K-Means'in algoritmasında rastgelelik olduğunu biliyorsunuz. Peki her çalıştırdığımda farklı sonuç üretecek ise ben bunu nasıl test edeceğim? Eğer buraya bir seed değeri verirseniz rastgele sayı üreticisi her zaman seede bağlı olarak aynı sayıları üreteceğinden böyle dertlerimiz kalmaz.
Metric
Uzaklık ölçüm metodunu seçmemizi sağlıyor kendisi gün itibariyle iki adet ölçüm metodu içeriyor.
Öklid (Euclidean)
İlki bir önceki yazıda da kullandığımız öklid uzaklığı ki formülü şu şekildeydi:
\sqrt{\sum_{i=1}^{n}{(q_i - p_i)^2}}Yine ince detaylara o yazıdan erişebilirsiniz. Ama ben yine de konuya ilişkin ufak bir görsel atayım 🙂
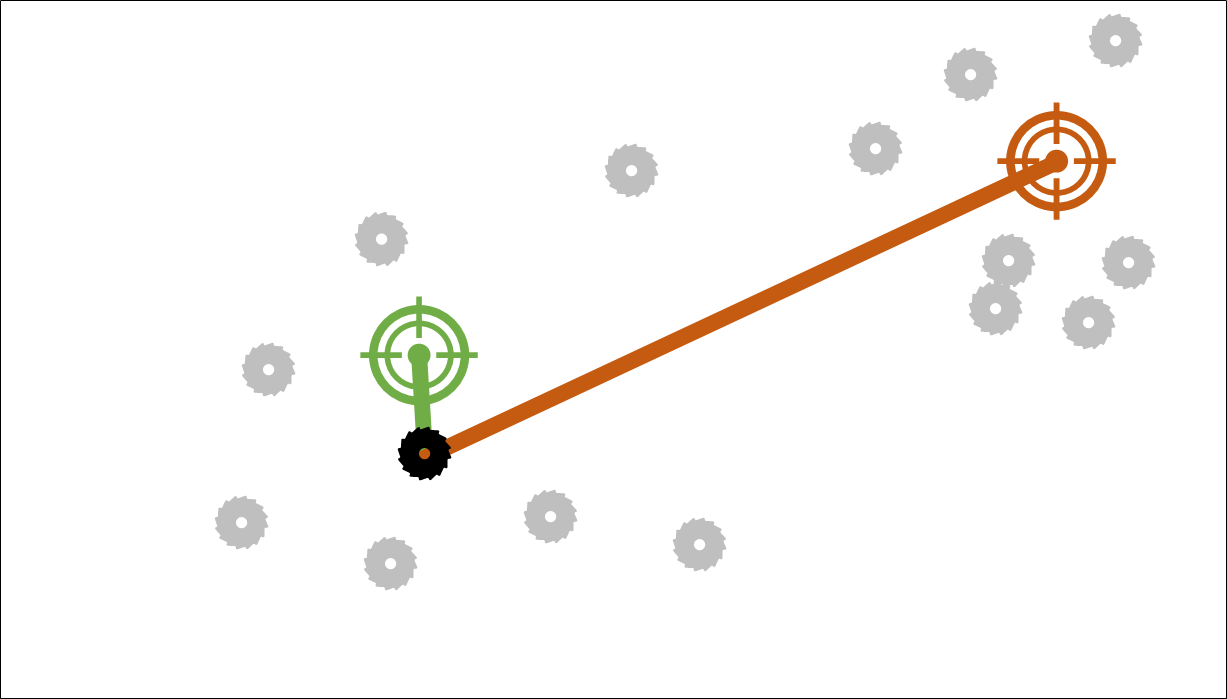
Örneğin bu görseldeki doğru parçaları karar aşamasındaki nokta için küme merkezlerine olan öklid uzaklıklarını simgeliyor. En yakın yeşil nokta olduğu için K-Means onu tercih edecektir.
Kosinüs Benzerliği (Cosine)
Merkez noktaya olan uzaklıklarına göre değil de merkez noktalara yapılan açıya göre demetleme işlemi yapmak istiyorsak bunu seçiyoruz. Genellikle metinlerin demetlenmesinde kullanılır.
\cos{\alpha} = \frac{\vec{d_1}\cdot\vec{d_2}}{\left \| \vec{d_1} \right \| \left \| \vec{d_2} \right \|}Formülün Türkçesi şu şekilde, d1 ve d2 satırlarının iç çarpımını (iki dizinin aynı sıradaki elemanlarını çarp sonra bu çarpımları topla) al ve d1 nın ve d2 nin uzunluklarının (orijine göre öklid uzaklıkları) çarpımına böl.Bu uzaklıklar konusunu ayrıca yazı konusu yapmak istediğimden detaya inmeyeceğim.
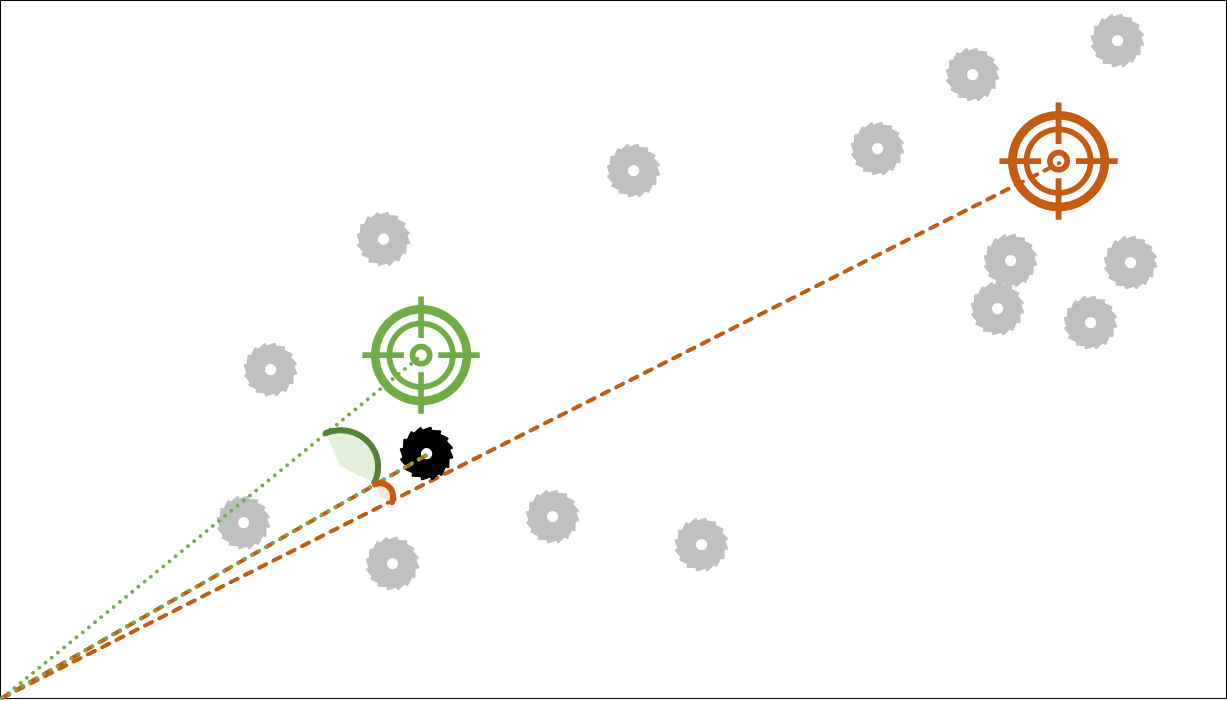
Öklid uzaklığındaki noktalara tekrar bakalım bu sefer kosinüs benzerliği ile atama işlemini gerçekleştirelim. Yeşil merkez noktanın, çalıştığımız küme ile orijinde yaptığı açı çok daha yüksektir. Bu sebeple bu durumda atama işlemi turuncu noktaya yapılacaktır.
Nihai ayarlar
Ayarları daha önce C# kodunu yazdığımız algoritmaya oldukça benzetecek şekilde ayarlıyoruz:
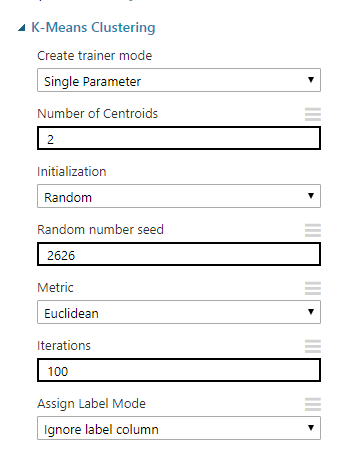
Devam
Mevcut durumda kaydedip çalıştırdığımızda "Train" kutucuğunun 2. çıktısını görselleştirdiğimiz vakit bizi şöyle bir ekran karşılamalı:
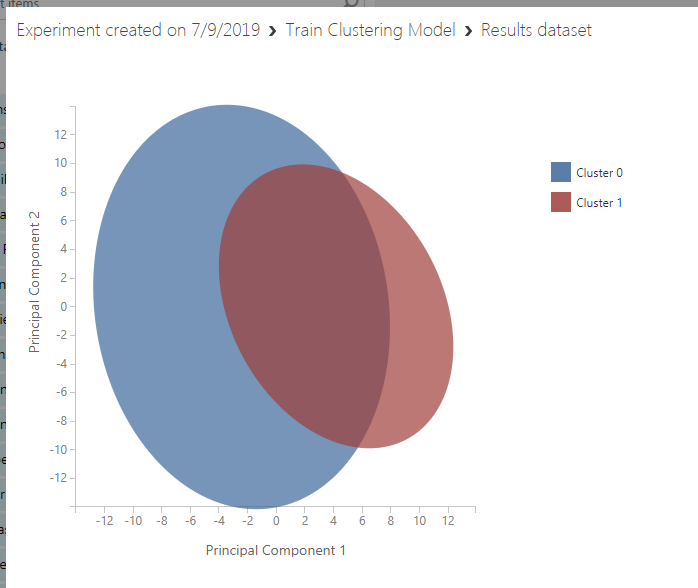
Gördüğünüz grafik, sonuçların Principle Component Analysis (PCA) algoritmasından geçmiş halinin görselleştirilmesinden oluşturulmuştur. Bu algoritma N boyutlu bir veri kümesini M boyuta indirgemeye yaramaktadır. Bu sayede "Curse Of Dimensionality" adı verilen problemin çözülmesi amaçlanır. Bu problem makine öğrenmesinin ilk konularındandır, daha önce işitmediyseniz kenara not alın. Grafik kümelerin dağılımını göstermek ve doğru yolda olduğumuzu anlamak adına önemlidir.
Grafik faydalı ama hangi satırın hangi kümeye atandığını net olarak söylemiyor. Bunu öğrenmek için tuval üzerine "Convert to dataset" kutucuğu bırakıyoruz.
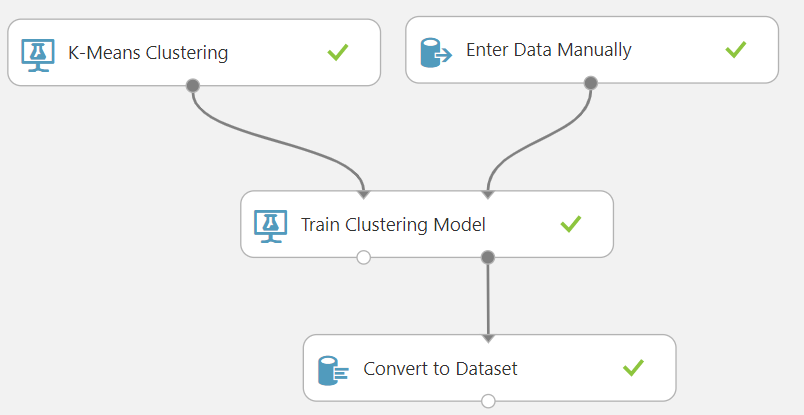
Demetleme işleminin ardından orijinal verimize 3 yeni kolon eklendi. Bunları görmek için kaydedip, çalıştırıyoruz ve "Convert the dataset" kutucuğunun çıktısını görselleştiriyoruz.
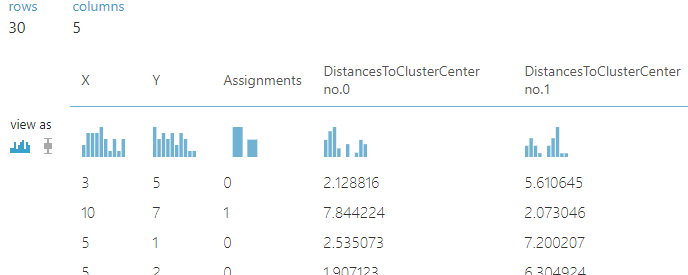
Görseldeki kolonlardan "X" ve "Y" zaten bizim verdiğimiz niteliklerdi. Yeni eklenen "Assigments" bu satırın hangi kümeye atandığını belirtiyor. Diğer iki kolon ise ilgili satırın küme merkezlerine olan uzaklığını gösteriyor. Bu sayı ne kadar az ise ilgili kümeye o kadar benzemektedir.
Peki ben sonuçları bildiğim bir formatta nasıl temin edebilirim? En kolayı veri setini CSV olarak alabilirsiniz. Bunun için "Convert to CSV" kutusunu tuvale bırakmanız yeterli olacaktır. Daha sonra veriyi "CSV" dosyası olarak indirip kullanabilirsiniz.
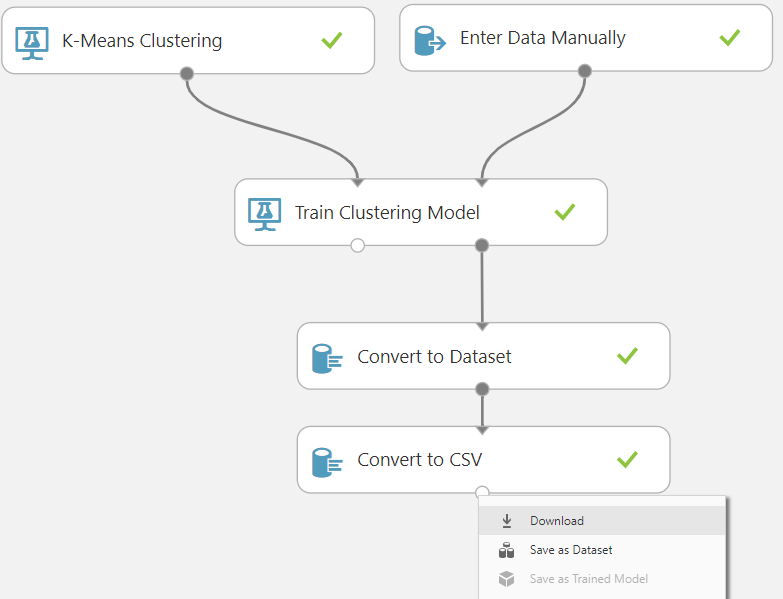
Peki Azure ML Studion fazla uzaklaşmadan ben bu sınıflandırma işini nasıl görselleştirebilirim. Tamam PCA bana az buçuk fikir verdi ama ben grafik üzerinde görmek istiyorum.
Bunu sağlamak için "Convert to Dataset" kutucuğunun çıktısına sağ tıklıyorum ve "Open in a new Notebook" seçeneğine gelip "Python 3" e tıklıyoruz. Bu işlemin ardından bizi bir Jupyter defteri karşılayacak. Aynı zamanda bu defter "My notebooks" altında kayıt ediliyor. Kapattıktan sonra deftere buradan devam edebilirsiniz. Defter ilk açıldığında bizi şöyle karşılayacak:
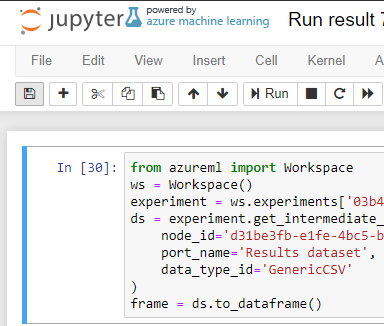
Buradaki ilk kod bloğu Azure ML Studio üzerindeki dataset kutumuzu Python ortamına bağlıyor ve frame adındaki bir değişkene atıyor. Ama henüz bu kod çalıştırılmadı. Kod bloklarını çalıştırmak için, ilgili blok seçili iken Shift + Enter kombinasyonuna basmamız gerekiyor. Bunu ilk kod bloğu için yapın.
Yeni bir kod bloğu eklemek için ALT + Enter kombinasyonunu kullanın. Şimdi frame içinde ne varmış görelim. Bunun için metin kutusuna "frame" yazın ve Shift + Enter'a basın. Sonuç şöyle olmalı:
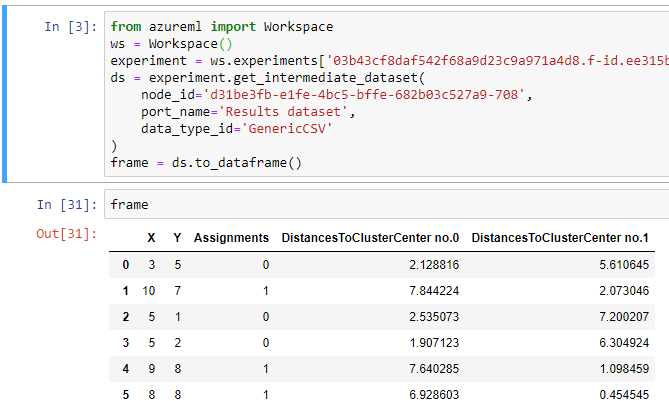
Bu gösterimi zaten tuval üzerinde de yapabiliyorduk. Grafik çizmek için ise matplotlibden yararlanacağız. Yeni bir kod bloğu açın ve bu sefer şu kodu yazın:
frame.plot.scatter(x='X',y='Y',c='Assignments')Bu arkadaşı çalıştırdığınız da ise sonuç şöyle görülmeli:
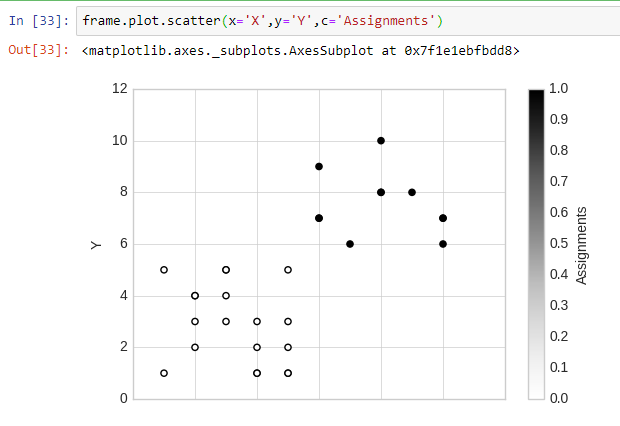
Farklı algoritmalarda görüşmek üzere.
